

14 Jun 2012 Mengoptimasi z/OS
Kenapa z/OS harus dioptimasi? Tidak harus! Tanpa dioptimasipun, kinerja z/OS sudah lebih optimal ketimbang OS manapun. Namun kita kehilangan salah satu kelebihan yang dimilikinya. Padahal kelebihan itu telah kita bayar 🙂
z/OS adalah OS mainframe yang memberikan keleluasaan terbesar kepada pengguna untuk mengoptimasi kinerjanya sesuai dengan karakteristik beban sistem yang ada. Workload Manager (WLM) adalah sarana untuk melakukan tuning kinerja z/OS. Topik ini tidak membahas soal optimasi aplikasinya. Karena topik ini tidak membahas teknik programming aplikasi. Lagipula, saya anggap aplikasi jaman sekarang, untuk komputer apa saja kurang lebihnya sama, berbasis web, SOA, RDBMS dsb yang rata-rata cenderung berorientasi layanan (service-oriented). Memang ada esensialitas z/OS yang tak tertandingi, yaitu kemampuanya menjalankan aplikasi legacy dari OS serumpun sejak MVS generasi pertama (awal dekade 1970). Dan yang lebih istimewa lagi, z/OS menyediakan penyambung (interface) untuk memlintir aplikasi legacy yang online hanya dengan dumb terminal 3270 menjadi client-server dengan workstation dan kini bahkan diplintir lagi menjadi aplikasi web. Mungkin semua akan saya tulis pada kesempatan lain. Kali ini khusus membahas soal optimasi z/OS saja.
Di satu sisi, z/OS merupakan OS yang paling manageable ketimbang OS manapun, karena hampir semua komponen bisa disesuaikan dengan keinginan pengguna. Mulai dari susnan dan isi panel-panelnya, nama-nama obyeknya (dataset, file, catalog, folder dsb), alokasi memori hingga mekanisme kerjanya, semua dapat dirubah sesuai dengan selera pengguna. Panel mulai dari panel ISPF hingga panel ZOSMF (web) bukan hanya configurable, namun bisa dirombak total atau bikin sendiri. Nama-nama obyek sistem juga bisa dirombak total jika mau. Alokasi peta memori, berapa yang shared, berapa yang exklusif, berapa yang V=R dan berapa maximum jumlah address space juga bisa diatur sesuai selera lokal. Mekanisme kerja sejak mekanisme loading apakah I/O dari disk (library) atau cash (VLF) atau dengan paging (LPA) atau bahkan sudah preloaded (FLPA) hingga model dispatching termasuk alokasi timeslice bisa diatur. Sejumlah fungsi OS juga boleh dikembangkan sesuai kebutuhan lokal. Pendek kata, pengguna seperti dimanjakan untuk melakukan perubahan apa saja sesuai selera, bila perlu lenyap penampilan z/OS dan menyublim menjadi OS lokal yang baru.
Di sisi lain, khususnya untuk merubah mekanisme kerja, disediakan ratusan parameter dan ratusan exit point yang semuanya menuntut penguasaan arsitektur hardware dan OS serta ketrampilan systems programming, komputasi dan statistika (queuing theory) yang benar-benar mumpuni. Tentu tidak setiap orang bisa melakukannya. Bahkan sementara orang mengatakan z/OS termasuk OS yang rumit dan sulit ditangai. Mereka lupa bahwa dengan default saja sudah cukup, sama dengan OS lain. Mereka lupa bahwa merubah mekanisme kerja OS lain jauh lebih sulit, karena mutlak harus dari sourcecodes setiap modul terkait, karena tidak disediakan parameter maupun exit point.
Bicara soal optimasi, ada 2 hal yang perlu dibahas, yaitu optimasi kinerja dan optimasi fungsi. Optimasi kinerja cukup dilakukan melalui parameter sistem. Sedangkan optimasi fungsi hanya dapat dilakukan dengan systems programming melalui exit point.
Optimasi dasar
Optimasi kinerja z/OS yang paling dasar adalah mengatur kesetimbangan beban. Anggaplah mula-mula cukup mengandalkan nilai-nilai default. Lantas kita amati kinerja sistem menggunakan sarana pemantau yang tersedia. Sebenarnya yang paling lazim semua pekerjaan di wilayah OS dilakukan dengan TSO/ISPF melalui terminal 3270. Karena kru OS dianggap pakar mainframe yang sudah sangat terbiasa menggunakan TSO/ISPF maupun terminal 3270. Sebenarnya tidak ada yng istimewa, karena penampilan ISPF full menu driven, tidak seperti SCO Unix maupun DOS yang harus selalu ingat command. Namun demikian, agar mudah dipahami pembaca yang belum menjadi pakar mainframe, saya pilih z/OSMF yang berbasis web. Harap dicatat bahwa z/OSMF adalah sarana baru yang hadir sejak z/OS V1R11 dan perlu WebSphere untuk menjalankannya. .
Optimasi kinerja dasar adalah menata semua beban disesuaikan dengan tingkat layanan atau service level (SL) yang direncanakan. Mula-mula kita amati kinerja sistem secara snapshot di saat peak untuk sekedar mendapat gambaran pembeban terkini. Kita tampilkan z/OSMF panel melalui browser yang biasa kita pakai. Gambar-gambar aman z/OSMF saya sunting dari publikasi IBM Redbooks SG24-7851-00.
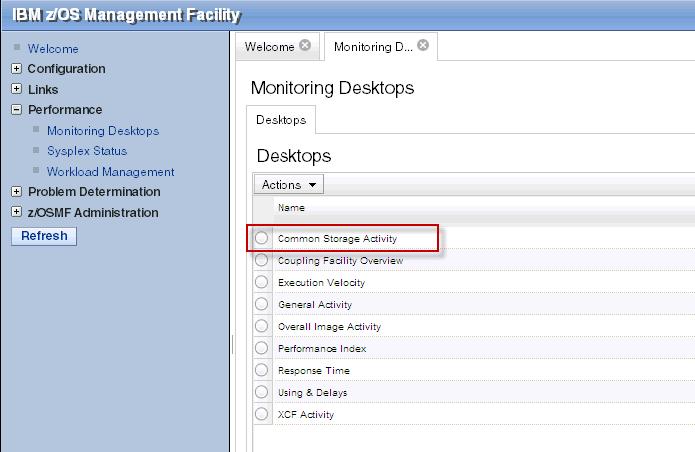
Mula-mula kita buka laman index zosmf dan ikuti petunjuk Performance -> Monitoring desktop untuk laman pilihan komponen mana yang akan kita lihat seperti pada gambar dibawah ini.

Dalam contoh ini, kita memilih untuk memantau pemakaian kapling shared segment memori yang disebut common storage area (CSA). Laman yang muncul adalah grafik sederhana seperti pada gambar di bawah ini. Grafik ini snapshot mencerminkan keadaan saat ini (sample terakhir). Lajur kiri menayangkan aktivitas CSA. Lajur kiri menayangkan system queue area (SQA). Baik lajur CSA maupun SQA, yang atas keseluruhannya dan yang bawah rinciannya per address space.

CSA maupun SQA dikonsumsi oleh proses mana saja yang memerlukan shared segment untuk berbagi dengan proses yang lain, baik dari address space yang sama maupun berbeda, baik user program maupun system program, termasuk bagian OS maupun system-level software di luar OS. Cara pemakaiannya ada yang sekali pakai ada pula yang presisten. Untuk melihat siapa saja yang sedang memakainya, lihat di bawahnya, yaitu rincian per address space.
Pemakaian CSA maupun SQA sangat frekuentif. Pembuat user program mungkin tidak tahu karena programnya tidak langsung berhubungan dengan CSA maupun SQA. Alokasinya berada di balik macro maupun system call yang mereka gunakan dalam program, misalnya ketika memanggil fungsi I/O atau networking. Sehingga tanpa disadari, mereka pun memakai cukup banyak bahkan intensif. Sedangkan systems program, selain yang dibalik macro dan/atau system call, sebagian memang sengaja mengapling CSA atau SQA untuk maksud tertentu. Dengan demikian bisa disimpulkan pemakaian CSA maupun SQA cukup sibuk. Sedangkan monitor, meskipun snapshot, menampilkan sample pengukuran yang dilakukan dalam selang waktu tertentu yang mungkin terlalu panjang untuk ukuran exekusi unit proses. Sehingga angka yang tampil adalah rata-rata dalam selang waktu sampling. Oleh karena itu, untuk amannya, rata-rata aktivitas CSA maupun SQA sebaiknya tidak melebihi 40%. Karena jika aktualnya pernah 100% dalam satu timeslice, maka timeslice berikutnya proses akan menunggu jika memerlukan alokasi baru CSA atau SQA, dan sisa timeslice dialihkan ke unit proses yang lain. Jika semua unit proses dalam lingkaran dispatch menunggu alokasi baru CSA atau SQA, berarti sistem berhenti. Hal semacam ini jangan pernah terjadi.
Detil per address space juga perlu dimonitor. Yang paling kritis adalah pemakaian presisten. Alokasi akan dipertahankan meskipun program sudah berhenti dan address space sudah digulung. Sehingga program harus merilisnya sebelum berakhir. Produk-produk software yang baru, kadang masih ketidaktelitian dalam hal ini. Mungkin dari puluhan atau ratusan alokasi, ada satu yang kelewatan. Dalam sehari dua hari mungkin belum kelihatan. Tetapi karena terakumulasi terus, bisa jadi dalam seminggu atau sebulan baru nampak rakusnya. Nah .. ini akan tampak di uraian detil di bagian bawah.
Untuk mendapatkan hasil pengukuran selama selang waktu tertentu, kita gunakan sarana yang dinamakan RMF dan hasilnya ditampilkan seperti pada gambar di bawah ini.

Selain aktivitas CSA dan SQA, masih banyak aktivitas lain yang harus dimonitor, terutama I/O, response time, performance index dll. Saya tidak akan bahas satu per satu disini karena tulisan ini bukan buku pelajaran. Intinya, menjadi systems engineer (SE) harus mumpuni seluk beluk kerja sistem, tidak boleh setengah-setengah jika yang kita pegang sistem yang mission-critical.
Setelah mengamati keseluruhan kinerja sistem, kini gilirannya merancang susunan prioritas sesuai SL yang kita harapkan. Secara ringkas, langkah-langkah yang harus kita tempuh setidaknya sbb:
- Bikin susunan beban atau workload. Tiap workload mencerminkan koleksi proses yang akan ditampilkan sebagai satu unit beban sistem. Ini sebenarnya sekedar definisi penamaan. Namun penetapan workload sebaiknya mencermin satu kesamaan tertentu, misalnya satu kesamaan dalam kepentingan bisnis.
- Bikin susunan service class atau klasifikasi layanan. Diharapkan service class mencerminkan koleksi proses dalam satu workload yang memiliki kesamaan karakteristik kinerja, yaitu:
– performance goal
– sumberdaya yang dikonsumsi
– tingkat prioritasnya dalam kepetingan bisnis. - Bikin rule klasifikasi untuk mengkaitkan task dengan service class
Masih ada beberapa langkah tambahan yang saya anggap tidak perlu dibahas disini, karena ini bukan buku atau bahan pelatihan.
Langkah (1), susunan workload, ibarat lahan kita bikin pembatasan pemetaan sektor, ada sektor bisnis, sektor pemukiman, sektor perkebunan dll. Dalam hal workload, umumnya ada transaksi batch, transaksi online, server based, dll. Kelpmpok batch kadang masih dipisahkan lagi atas high-performance, medium dan low. Demikian pula workload yang lain. Penamaannya terserah kita, yang penting unik dan sebaiknya mencerminkan, misalnya HIBATCH, LOBATCH, HIONLINE dll.
Langkah (2) susunan service class, ibarat lahan sudah mulai menyusun infrastruktur per sektor. Untuk bisnis harus ada jalan raya, lapangan parkir umum, listrik dll. Untuk pemukiman harus ada jalan yang layak, saluran air minum, listrik dll. Dalam hal service class, kita harus menentukan performance goal, durasi pencapaian dan prioritas dispatcing. Penamaannya terserah kita, yang penting unik dan sebaiknya mencerminkan, misalnya HISTC dan LOSTC untuk workload HIBATCH, HIJOB dan LOJOB untuk LOBATCH, HICICS dan LOCICS untuk HIONLINE dst.
Langkah (3), rule klasifikasi, ibarat lahan sudah mulai mengisi tiap sektor yang infrastrukturnya sudah siap. Di sektor bisnis dibangun ruko, sektor pemukiman dibangun rumah dst. Dalam hal rule ini, kita mengkaitkan task mana untuk dapat service class yang mana. Pengkaitan bisa berdasarkan nama job, nama plan (untuk DB), nama transaksi (untuk CICS) dsb.
Konfigurasi rancangan kinerja yang dihasilkan 3 langkah di atas disebut sebuah kebijakan kinerja atau performance policy. Kita bisa bikin policy sebanyak-banyaknya, tetapi pada satu saat hanya satu yang aktif. Tiap policy bisa diaktifkan kapan saja, sehingga ada gunanya punya banyak policy jika model kinerja kita berganti-ganti menyesuaikan situasi. Berikut ini laman z/OSMF yang menampilkan 3 policy yang sudah dibikin.

Panel laman ini menyediakan pilihan aksi yang dapat kita lakukan untuk setiap policy yang ada, seperti contoh laman di bawah ini. Kita bisa menghapus, menyimpan, mengaktifkan, mencetak dsb terhadap setiap policy, maupun bikin policy baru. Untuk sistem multi-host dengan konfigurasi parallel sysplex, misal GDPS, satu policy berlaku untuk seluruh host.

Sebenarnya bagian paling inti dari pekerjaan ini adalah merancang service class. Karena disana kita memasuki rincian teknis mengurai kinerja sistem secara kuantitatif. Mula-mula kita isi nama-nama service class yang akan kita definisikan. Gambar berikut ini adalah laman z/OSMF yang menayangkan daftar service class yang telah kita buat.
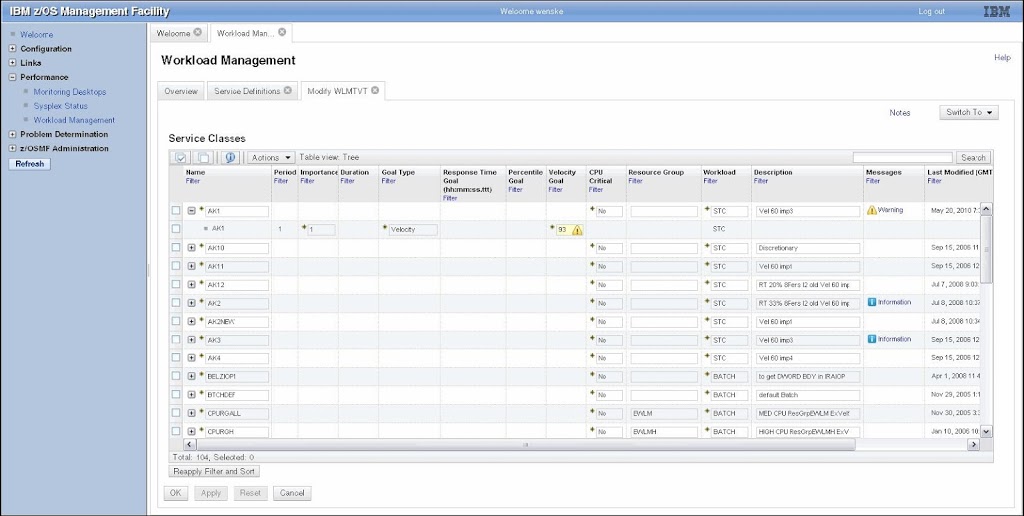
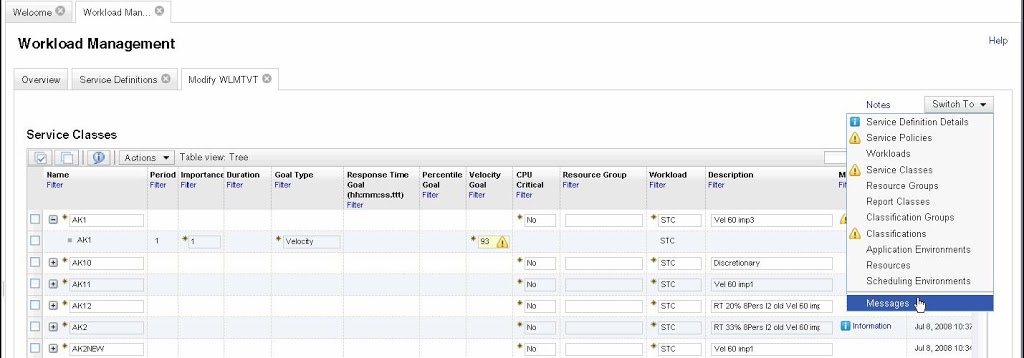
Dari laman ini kita mulai mengisi detil nilai setiap parameter WLM. Tidak harus langsung selesai seluruh service class. Kita juga bisa loncat ke laman lain melalui sarana switch seperti pada gambar di bawah ini. Namun policy tidak bisa diaktifkan sebelum semua parameter rampung diisi.
Parameter-parameter yang harus dirampungkan untuk setiap service class adalah:
- Business importance
- Performance goal
- Resource requirement
Business importance merupakan cerminan langsung prioritas. Nilainya diskret dari 1 sampai dengan 5, dimana 1 merupakan prioritas tertinggi dan 5 terendah. Artinya ketika beberapa task yang memiliki performance goal yang sama berlomba mendapatkan sumberdaya sistem, maka yang nilainya kecil didahulukan. Dengan kata lain, business importance ini mencerminkan dispatching priority dengan nilai berbanding terbalik.
Performance goal merupakan kinerja yang diharapkan. Ada 3 macam performance goal yang bisa kita pilih dan nyatakan untuk setiap service class period melalui parameter WLM, yaitu (1) response time, (2) velocity dan (3) discretionary.
Response time goal adalah harapan kecepatan task menyelesaikan setiap transaksi. Tentu hanya berlaku untuk jenis-jenis task yang melayani transaksi singkat, yaitu transaksi online seperti CICS, HTTP dan jenis-jenis aplikasi berbasis message, maupun transaksi internal seperti DB query dsb. Response time goal ini ada 2 macam, yaitu, response time rata-rata dan dengan persentil. Response time rata-rata adalah berharap keseluruhan response time seperti yang dinyatakan dalam parameter WLM. Sedangkan response time dengan persentil berharap response time yang dinyatakan dalam parameter WLM dipenuh dengan persentase tertentu yang juga dinyatakan dalam parameter WLM. Misalnya response time 0.01 detik 60%, artinya 60% transaksi mencapai response time 0.01 detik. Response time rata-rata merupakan goal dengan derajat tertinggi.
Velocity goal adalah seberapa cepat unit proses yang sudah siap untuk mendapatkan sumberdaya. Nilai goal ini dinyatakan dalam angka persen karena memang mirip peluang. Velocity goal dinyatakan 70% artinya, peluang untuk mendapatkan sumberdaya sistem ketika sebuah unit proses siap adalah 70%. Velocity goal derajatnya di bawah response time dengan persentil. Velocity goal berlaku untuk hampir seluruh jenis task, kecuali CICS dan IMS.
Discretionary goal adalah default untuk kebanyakan task, artinya tidak ada goal. Sepenuhnya diserahkan kepada OS untuk diatur sesuai keadaan.
Untuk beberapa jenis workload seperti TSO dan program batch pada umumnya, performance goal bisa dipecah menjadi periodik. Masing-masing perioda boleh menggunakan goal yang berbeda-beda, tapi harus sesuai dengan derajatnya. Perioda tertentu derajat goalnya importance-nya tidak boleh lebih tinggi dari perioda sebelumnya. Masing-masing perioda harus dibatasi durasinya, kecuali yang terakhir.
Menetapkan nilai-nilai service class harus memahami arsitektur sistem dan kepentingan bisnis. Misalnya, DBMS warganegara (WN) dalam e-Gov adalah aplikasi yang paling penting, karena melandasi hampir seluruh aplikasi yang terkait dengan WN, seperti misalnya e-KTP (DepDagri), INAFIS (Polri), Daftar pemilih (KPU), Pajak individu (DepKeu), statistik ekonomi rakyat (BPS) dll. Sehingga prioritas DB2 (DB engine), Comm Server (VTAM dan TCPIP stack) maupun SOAP (misal HTTPD1 atau SOLA) juga harus lebih tinggi dari semua aplikasi tersebut. DB2 dan VTAM boleh sama, karena satu sama lain tidak saling ketergantungan. Tetapi VTAM harus lebih tinggi dari TCPIP, karena VTAM berperan sebagai frameworknya dimana TCPIP tergantung padanya. Demikian pula SOAP, harus di bawah TCPIP karena jeroannya adalah socket programming yang merupakan aplikasi TCPIP. Yang harus dicermati, tinggi-rendahnya prioritas apakah cukup dinyatakan dengan nilai importance saja, ataukah sampai pada performance goal.
Prioritas I/O bisa diatur untuk mengikuti performance goal maupun sekedar sesuai dispatching priority. Ini juga harus dicermati agar sesuai dengan karakteristik beban. Yang jelas, performance goal akan menjadi penentu pula manakala prioritasnya sama.
Optimasi lanjutan
Semua optimasi di luar jangkauan WLM kita sebut optimasi lanjutan, antara lain optimasi I/O, spool, paging/swapping, memori dan masih banyak lagi. Optimasi I/O dan paging/swapping ada kemiripan, yang penting hindari lebih dari satu dataset dalam satu disk volume ber-I/O pada saat yang sama. Berarti jangan ada 2 paging/swapping dataset berada bersama dalam disk volume yang sama. Jangan ada paging/swapping dataset berada bersama catalog dalam disk volume yang sama. Disk volume tempat paging/swapping dataset atau catalog jangan diisi dataset lain kecuali aktivitasnya sangat rendah dan tidak di saat peak.
Spool agak sedikit berbeda. Selain tidak boleh berada dalam satu disk volume dengan paging/swapping dataset, catalog maupun dataset umum yang aktif, spool juga sebaiknya dipecah dalam beberapa volume meskipun kapasitas volume cukup. Hal ini dikarenakan hampir semua task harus mendapat pelayanan spooling dari JES dan cara JES melakukannya simultan melalui mekanisme multitasking. Dengan memperbanyak spool, berarti memberikan kelancaran, karena memungkinkan I/O spooling dilakukan paralel antar spool volume.
Optimasi memori selain pengkaplingan common storage area (CSA), system queue area (SQA) dan link pack area (LPA) yang optimal, juga perekrutan modul-modul program kedalam LPA serta mengoptimasi VLF. Alokasi CSA dan SQA telah di bahas di atas, yang penting pemakaiannya tidak melebihi 40% dari pengukuran alat pemantau. Menyatakanya melalui parameter CSA dan SQA di member IEASYSxx di library parameter milik sistem (PARMLIB), umumnya SYS1.PARMLIB.
Sedangkan LPA alokasinya otomatis sesuai dengan total besarnya seluruh modul program yang dimuat. LPA sangat bermanfaat mengurangi overhead ketika sebuah modul program diangkut ke memori untuk diexekusi. Tanpa LPA, pengangkutan dilakukan dengan I/O biasa dari disk (dimana modul berada) ke memori. Tetapi jika dengan LPA, seluruh modul yang telah didaftarkan ke LPA akan diangkut ke LPA ketika sistem di-boot dengan parameter CLPA dan disimpan disana sampai boot CLPA berikutnya. Ketika sebuah modul program akan diexekusi, OS melihat terlebih dulu apakah modul tersebut di LPA. Jika iya, maka tidak perlu loading dari disk, melainkan langsung exekusi. Mekanisme ini sangat menguntungkan karena meniadakan I/O. Jika ternyata sebagian sudah paged-out, modul harus paged-in, yang meskipun ada overhead I/O, namun menggunakan algoritma paging yang jauh lebih cepat dan efisien. . Terlebih jika modul tersebut ternyata mendukung mekanisme multitasking, selain loading lebih cepat (tak ada loading), juga lebih efisien, karena tidak perlu ada duplikasi di memori.
Namun demikian, tidak semua modul bisa dimasukkan ke dalam LPA. Modul harus reentrant yang artinya tidak menggunakan bagian dari modul tersebut sebagai variable. Sehingga tidak perlu ada duplikasi di memori ketika modul tersebut diexekusi oleh lebih dari satu task. Lebih lanjut soal multitasking dan reentrancy silakan menyimak systems programming lanjutan.
Optimasi sarana pengamanan
Kita tidak akan membahas bagaimana menyusun rule keamanan sistem, enkripsi, SSL dlsb. Pasti membosankan untuk dibaca dan menulisnya pun capek. Yang kita bahas disini justru bagaimana mempersiapkan sarana pengamanan seoptimal mungkin. Apa yang dimaksudkan? Sebelum melangkah lebih jauh, mari kita renungkan mekanisme yang paling lazim sbb:
- Semua policy dan parameter keamanan sistem telah dipersiapkan dengan matang oleh SE ketika sistem masih di fase pembangunan (development system). Puncak kewenangan atas sistem pengamanan berada di special user atau super user dan dikuasai sepenuhnya oleh SE.
- Lantas masuk fase pengujian (test system). Di fase ini, sistem mengalami serangkaian pengujian dan koreksi, termasuk sektor keamanannya. Setelah dinyatakan lulus, special user atau super user diserahkan kepada security admin. Semua userid SDM pembangunan, seperti SE, programmer dan analyst dibekukan. Semua userid SDM pendukung, seperti system admin, system support, network support dan DB support, dikurangi kewenangan aksesnya hanya sebatas operational parameters. Persis sebelum masuk ke fase produksi, semua userid tester (QA) pun dibekukan.
- Finalnya adalah memasuki fase produksi. Di fase ini, sudah tidak ada lagi lubang akses selain operational. Tidak ada celah sedikit pun untuk merubah satu bit pun obyek sistem, selain operational parameters oleh sysadmin atau SDM support. Perubahan yang ada hanyalah kontens aplikasi oleh user yang berwenang sesuai siklus produksi sehari-hari.
Sepertinya sistem di fase produksi sudah sedemikian aman. Apalagi mainframe yang telah kesohor sebagai sistem paling aman. Tentu tinggal menjalankan operasi sehari-hari tanpa ada keraguan soal keamanan. Satu-satunya celah untuk menerobos hanyalah security admin yang masih memegang special user atau super user. Jadi kalau ada kebobolan, mula-mula panggil auditor yang meluluskan ketika di fase pengujian. Jika auditor bisa membuktikan adanya perubahan policy, maka security admin lah yang harus bertanggungjawab.
Sepertinya penyelesaian di atas mudah dilakukan. Yang patut dicermati, apakah sistem pulih seperti sediakala setelah penyebab kebobolan ditemukan dan divonis? Pasti banyak yang meragukan! Maka, yang lebih penting lagi adalah bagaimana mencegah agar tidak terjadi kebobolan. Dengan kata lain, bagaimana caranya agar security admin pun tidak punya peluang untuk membobol sistem. Mungkinkah?
Jawabnya MUNGKIN!!! Disinilah perlunya SE, tapi SE yang benar-benar systems engineer, bukan cuman yang tertulis di kartu nama. Apa yang harus dilakukan?
Mula-mula kita cermati dulu bagaimana caranya security admin membobol sistem. Dia satu-satunya orang yang memiliki special authority untuk melakukan apa saja. Bila dia bodoh, dia akan lakukan dengan userid-nya. Tapi bisa juga dengan sedikit kecerdasan, bisa dengan cara memberikan otoritas pada userid lain untuk melakukan pembobolan dan setelah itu otoritas tersebut dicabut lagi. Bisa juga bikin userid baru dengan otoritas yang cukup untuk melakukan pembobolan dan setelah itu dia hapus lagi. Syslog dan blackbox (SMF) nya bisa juga dia hapus. Tetap masih bisa dilacak, namun sistem sudah bobol.
Jadi… satu-satunya solusi adalah TIDAK MEMBERIKAN SPECIAL AUTHORITY kepada security admin. Weleh… nggak bisa kerja donk dia? User memang disaranai agar bisa signup bikin akun sendiri. Tapi untuk memberikan approval, kan harus memiliki kewenangan. Apalagi jika dia ternyata anggota baru kru produksi yang tentunya memerlukan kewenangan lebih dari sekedar user biasa, tentu hanya bisa dilakukan melalui userid yang memiliki special authority. Bagaimana caranya tidak ada special user?
Caranya, harus dipersiapkan server task yang running sebagai STC Untuk memudahkan, katakanlah kita beri nama SECSERV. SECSERV inilah yang memiliki special authority. Sedangkan userid milik security admin adalah userid biasa tanpa special authority. Untuk memudahkan, kita namai SECADMIN. SECSERV bekerja secara event-based menangkap command yang diisu oleh SECADMIN. Hanya command yang tidak melanggar security policy saja yang dikabulkan exekusinya. Command yang melanggar security policy dicatat dalam blackbox dan dirilis dalam laporan reguler. Dengan demikian, security admin bukan saja tidak bisa membobol sistem, mencoba pun langsung tertangkap basah.
SECSERV ini sangat sederhana jika diimplemen dengan sarana otomasi seperti zJOS/Sekar dari NSI atau produk serupa dari IBM, CA, BMC atau ASG. Cukup dengan beberapa baris script sederhana. Tetapi kita harus membayar produk otomasi tersebut yang harganya cukup mahal. Tanpa sarana otomasi, tentu tidak mudah membikin SECSERV. Diperlukan ketrampilan systems programming yang cukup mumpuni. Jika anda berani pakai produk tanpa support, NSI juga menyediakan sarana otomasi gratis 🙂
(bersambung…)
Topik-topik terkait
- OS Mainframe
- Komputer Mainframe
- GDPS – Konfigurasi Sistem Komputer Antar Kota Antar Propinsi
- Downsize – Manfaat apa Mudharat?
- Mainframe z/Enterprise, Cara Jitu Beternak Server
- Capacity Planning untukVirtualisasi
- Mainframe Solusi Paling Jitu untuk e-Gov
- Web Server Sederhana Berbahanbaku Rexx untuk z/OS
- Virtualisasi dengan z/VM makin Heboh
- Systems Programming 2 (lanjutan)
- Awan Cumulonimbus Hadir di Jagat IT
No Comments